人脸识别之bbox【det_10g】-ncnn(c++)

det_10g是insightface 人脸框图和人脸关键点的分类,最终能够得到人脸框图bbox,分值还有人脸五官(眼x2、鼻子x1、嘴巴x2)
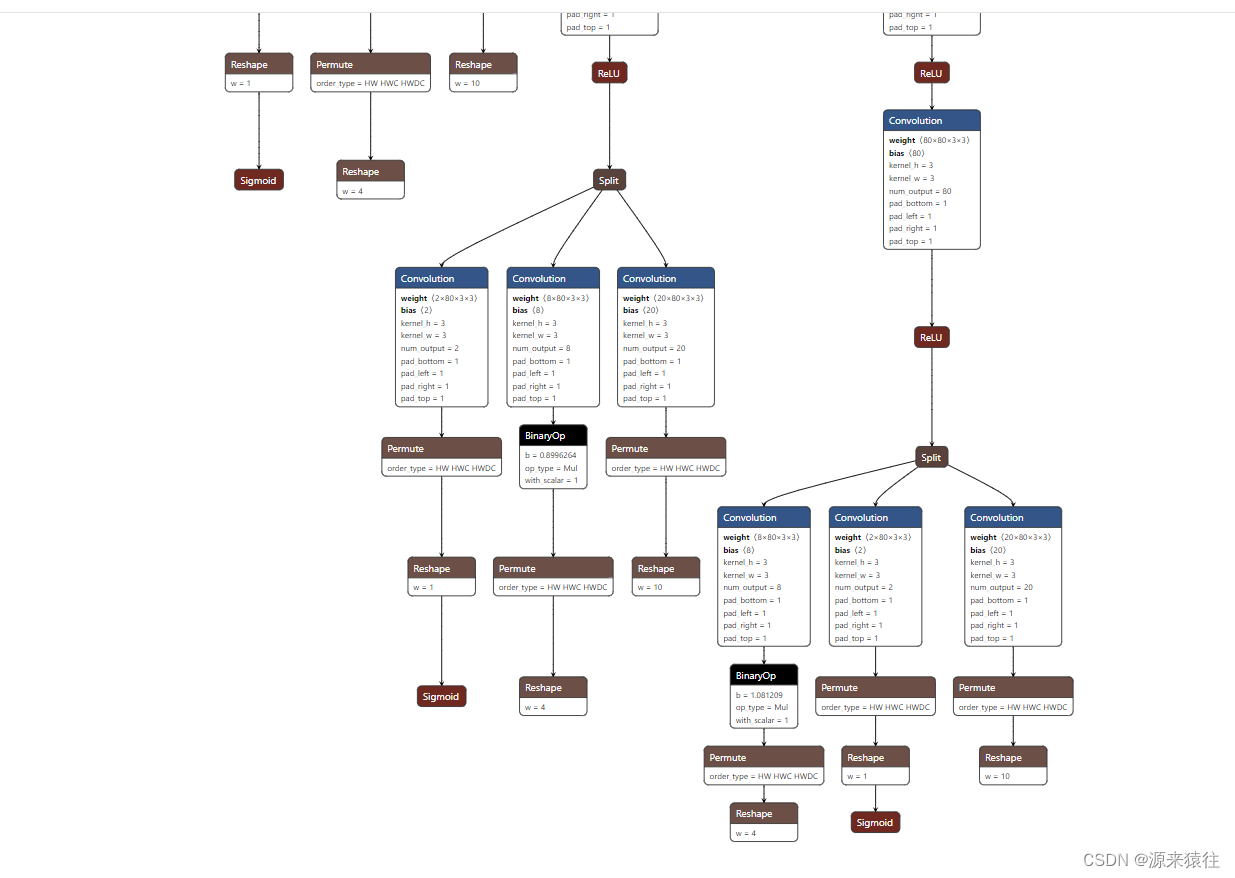
由于我这里没有采用最终结果,通过onnx转换为ncnn,所以后面的步骤结果丢弃了,具体可以看另外一篇博文:模型onnx转ncnn小记-CSDN博客
在python的时候输入和ncnn(c++)入参还是有些区别
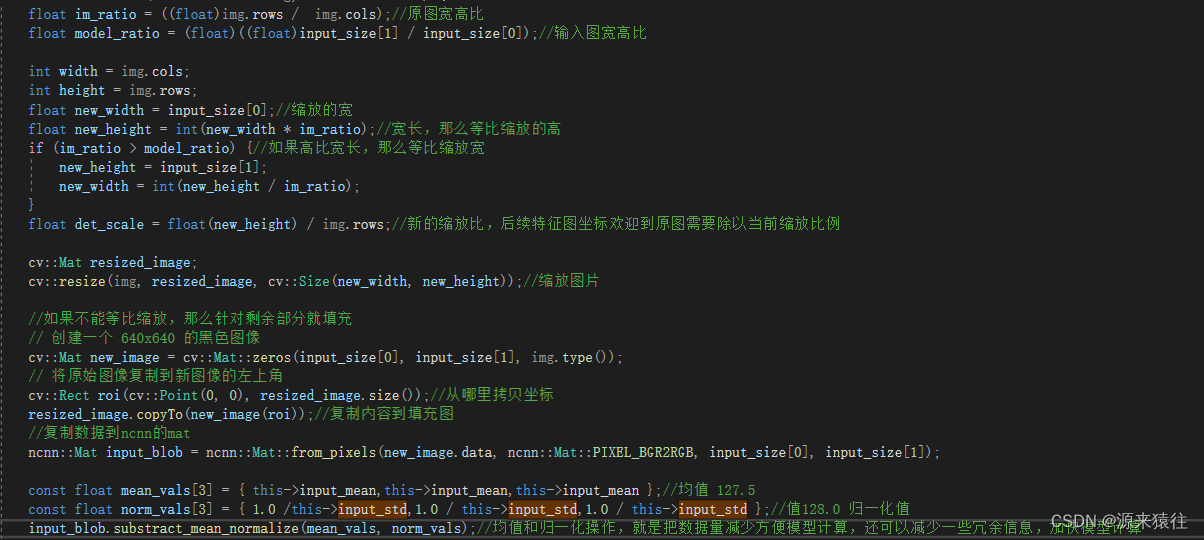
由于模型的输入是我这边选择的是1x3x640x640,所以针对输入的图片需要进行处理,首先进行等比缩放和数据的差值和归一化处理
把输入得到如下,9个结果
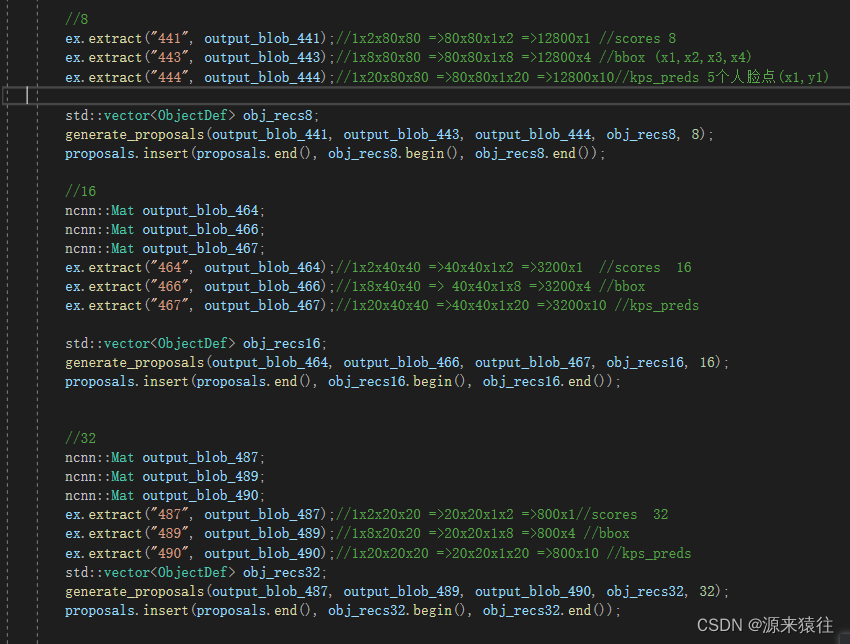
通过获取(441,443,444),(464,466,467),(487,489,490)
可以分别得到步长8, 16, 32 的三组数据,可以先了解下,目标候选框bbox的基础知识
需要分别计算步长8、16和32的目标数据,下面是步骤
变换维度,方便处理和理解。
他的一组数据是(441,443,444),获取的大小是:scores=》1x2x80x80、bboxs=>1x8x80x80、kps=>1x20x80x80
通过insightface的源码可以看到,num_anchors = 2,每个位置的目标框是两组,正常来说是黑白图两种,既然是同一个位置,那么可以合并一起,所以。
1、scores:1x2x80x80 意思就是有2张图 ,每张图大小是80x80,有这么多分值,我们可以通过阈值把大多数的点过滤出去,默认的阈值是0.5.
2、bboxs: 1x8x80x80 每一个分数对应的四个点(x1,y1,x2,y2)*注意这个点是距离原点的相对值,还是需要计算的,这里1x8 前面1~4 是一个矩形框的点,后面的4~8是另一张图的矩形框坐标点,就是黑白图。
3、kps:1x20x80x80 每一个分数对应的五官坐标点(x,y)*注意这个点是距离原点的相对值,还是需要计算的,这里1~10 是一组坐标点,另外的10~20是另外一张图的一组坐标点,分开计算就行。
这里获取的分数scores 需要做一个sigmoid,让他映射到0~1,方便后面和阈值比较。
具体c++的sigmoid
1、坐标放大
这里的bbox和kps都需要乘以8 变换为原有的,之前处理特征值做了压缩处理,压缩了8倍
每个坐标值都x8 得到原有特征图的坐标点。
bbox= bbox * 8
kps = kps * 8
2、求出真正的缩放值
bbox,这里的点都是一个偏移值,那么真正的坐标是怎么样的了,这里我们的这里返回特征图是80x80,由于这里的步长都是8,那么每个点就是这样排序下去,具体如下:
总共就是80x80的数据格式点
把每个点的坐标减去bbox[0]和bbox[1]得到左上角的(x1,y1)
把每个点的坐标减去bbox[2]和bbox[3]得到右上角的(x2,y2)
这样就得到了整个的bbox的坐标值
kps:其实也是一样,他是kps 5组x和y,分别添加上特征图的坐标点就行了,这里不需要减去
类似:bbox[0] + kps[n],bbox[1] + kps[n+1]
这样就求出kps的五个坐标点
其实应该先求出分数,然后再根据分数是否符合再求出坐标点,这样效率高点,这里为了理解过程就没有考虑效率问题了。
1、根据scores所有的分值进行过滤,过滤出大于等于0.5的阈值,得到一个分值列表
2、根据过滤的列表,把kps和bbox 也过滤下,去掉分值较低的
重复上面步骤,依次求出步长16和32的值,然后把结果放到一个列表,按得分份排序,方便后面的NMS计算,最终一个目标对应一个方框。
1、通过分值得到了不少的坐标点bbox,但是这些框很有可能是有重复的,这里需要用NMS进行过滤
过滤的规则就是通过IOU进行合并,当计算出的IOU大于阈值这里的阈值是默认0.4,那么就合并候选框,当然是把分值低的合并给高的,所以为啥前面要进行排序了。
IOU其实就计算两个框相交的面积
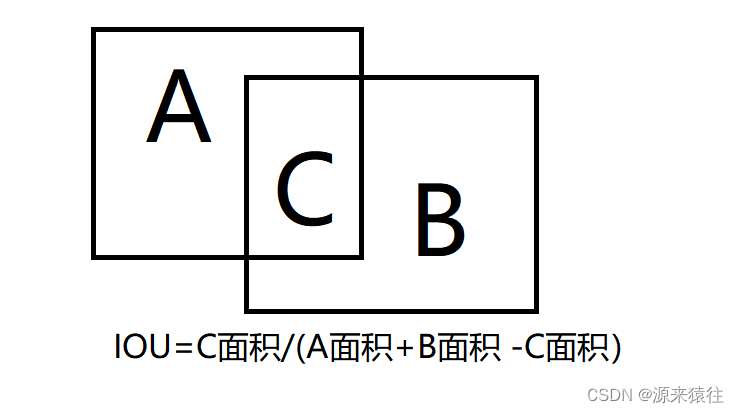
看着复杂,其实计算还是挺简单的,比如
假设:A坐标(x1,y1)(x2,y2) B坐标(x3,y3)(x4,y4)
上面的坐标都是左上角和右下角坐标,几个坐标可以合并成一个矩形框
A的面积:(x2-x1) *(y2-y1)
B的面积:(x4-x3)*(y4-y3)
根据上面可以求出C的宽和高:x4=(Min(x4,x2) - Max( x3,x1)) *( Min(y4,y2)-Max(y3,y1))
当然如果求出C的宽和高小于0,那么说明A和B没有相交不需要合并。
IOU=C面积/(A面积+B面积-C面积)
如果这个IOU大于我们设置的阈值这里是0.4,那么就进行合并选择得分高的
通过轮询把所有的候选框都过滤出来,就得到了最终的候选框。
具体可以查询文章 睿智的目标检测1——IOU的概念与python实例-CSDN博客
核心部分代码:(这里没有进行转换了,直接采用mat计算,通过分值过滤,最后计算出人脸关键点和bbox边框)这样效率会稍微高点。
记得模型得出来的bbox和特征值,都是一个偏离值,最后需要乘以步长,然后如果需要再原图进行展示的话,还需要对应特征图640x640和原图的比例展示,后面才可以得出原图的坐标
下面是得出特征图的坐标值
其他极大值可以采用其他的我这里是采用的yolo的,得到最终效果如下
获取得到了人脸框图和人脸关键点

本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.dbeile.cn/news/2211.html






最新文章
-

卖二手手机去哪里卖(卖二手手机在哪卖比较好)
2025-12-15 -
卫星地图下载手机版(卫星地图下载手机版官方)
2025-12-15 -
三千左右性价比高的手机(三千左右性价比高的手机排行榜)
2025-12-15 -

vivo手机配件(vivo手机配件真伪查询)
2025-12-15 -

手机客户端怎么登录(手机客户端怎么登录两个微信)
2025-12-15 -

oppo手机真伪(oppo手机真伪查询)
2025-12-15 -

iphone备份到新手机(iphone备份到新iphone)
2025-12-15 -

小米手机定位(小米手机定位华为手机位置怎么设置)
2025-12-15
热门文章
-

碰一碰收款码申请攻略(详细步骤和注意事项)
2024-12-26 -

33个适合新手投稿的公众号!
2024-12-12 -

2023年中国十大搜索引擎排名及分析
2024-12-08 -

微信碰一碰支付设置详解,如何轻松开启你的移动支付新体验_权限解释落实
2024-12-20 -
数字人民币真的来了!已进入微信,碰一碰就能付钱,教你怎么使用
2024-12-20 -

百度地图在哪看交易记录 百度地图看交易记录方法【教程】
2024-12-12 -

华为副总裁邓泰华一行到访智行者 推进双方深入合作
2024-12-08 -

400106(信威集团)的重组已经成功。信威集团在2024年完成了与天骄的重组,
2024-12-08