python爬取百度图片的思路与代码(最后附上了代码)

python爬取百度图片总体来说是比较简单的。爬虫一个网站,爬取百度图片的思路也是很有迹可循的。思路分为两大部分。第一部分(对百度图片的网页分析):百度图片是一个动态网页,怎么判断一个网页是动态网页或者说是个静态网页。也比较简单,网络上的资源也很多。简单说:如果你想爬取的内容,在页面源代码中很少(不全or没有),网址带有标志性的?。基本上就是动态网页。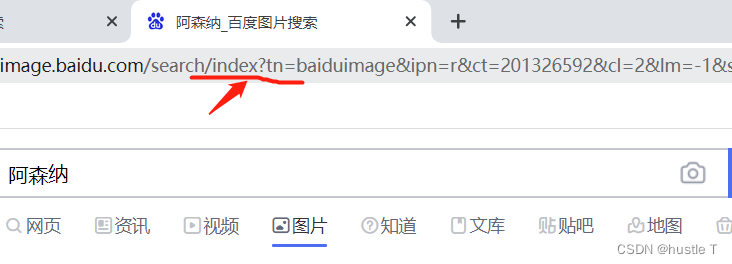
所以基本判断百度图片的网页是一个动态网页。这种与数据库不断交互的动态网页。我们在页面源代码中是拿不到照片地址的,或者说可能有20张的图吧(在有些网站中)。而静态网页是基本上全部内容我们在页面源代码都可以找到。所以第一部分的思路分析完成即我们针对动态网页进行爬取。 思路第二部分(代码实现爬取图片):首先打开浏览器的开发者工具(F12),然后锁定network(网络),再锁定fetch/xhr后。json中,就藏着一个个图像的相关信息。上图吧!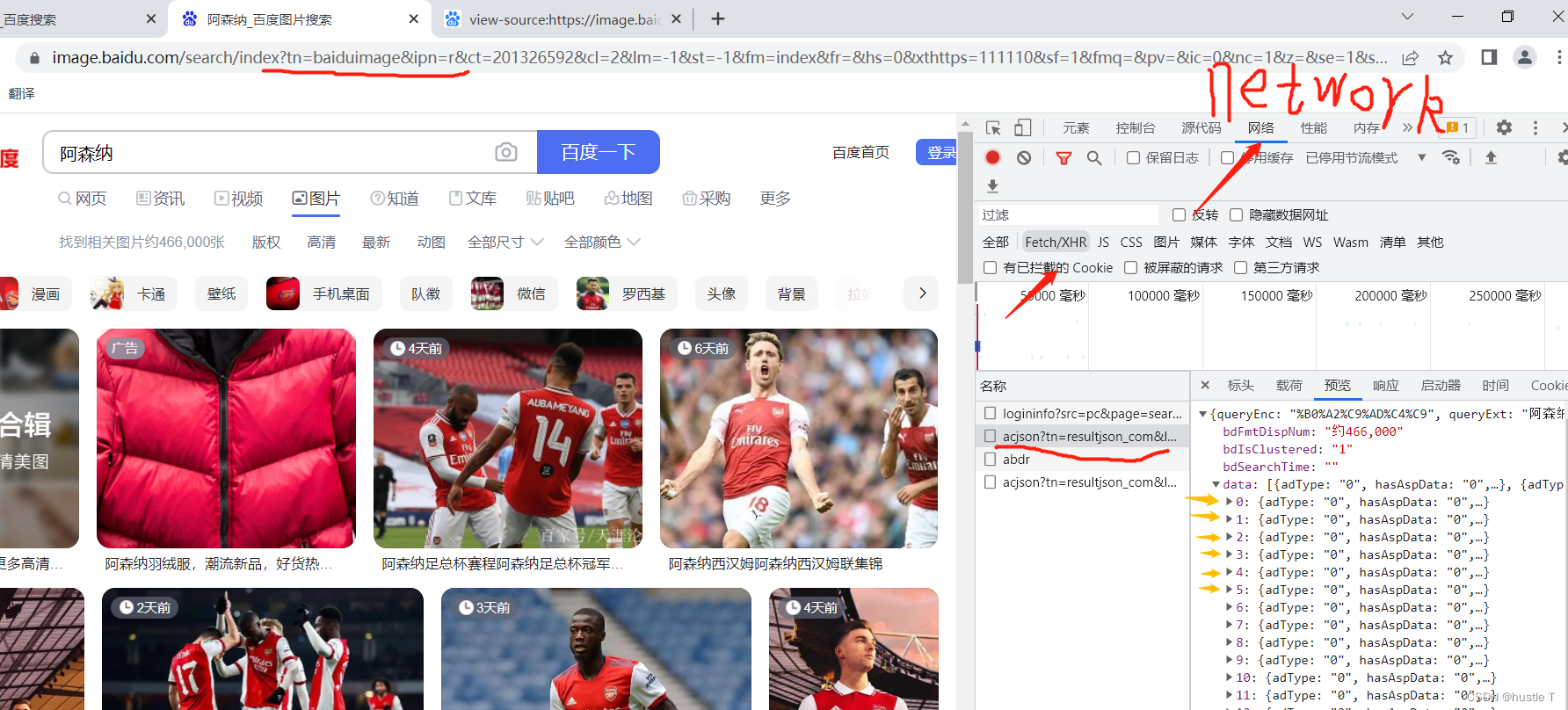
每当你访问你继续访问更多的照片,那么它又会传入一个新的以acjson开头的文件,,这就能很形象的感觉到动态了。而再这些以acjson开头的文件中,其页面源代码包含了其新的照片的访问地址,你只需要让程序去访问acjson的网页里面的源代码,就可以利用正则表达式去匹配出每个照片的地址,最后访问图片,下载到你的电脑上。或者其他的地方。思路就是如此。所以找到这些acjson文件的规律:每个里面的data数有三十个对应三十张照片,其acjson的url地址pn每次以三十为等差数列。那么其规律就出来了。我们其实嵌套两个循环就可以完成这个demo了,第一层访问acjson开头的文件的源代码,第二层就是每张照片的url,最后写入到电脑中。完成!!! 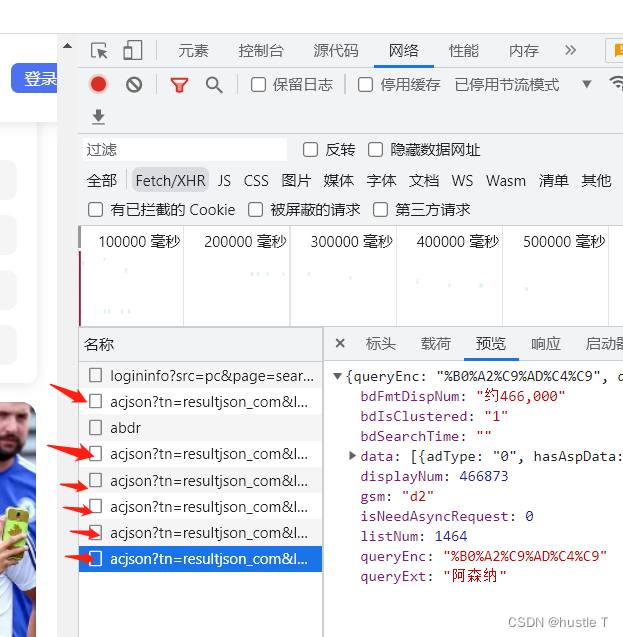
acjson的url地址在标头中,其规律pn的变化(后面的其他参数不用管的) 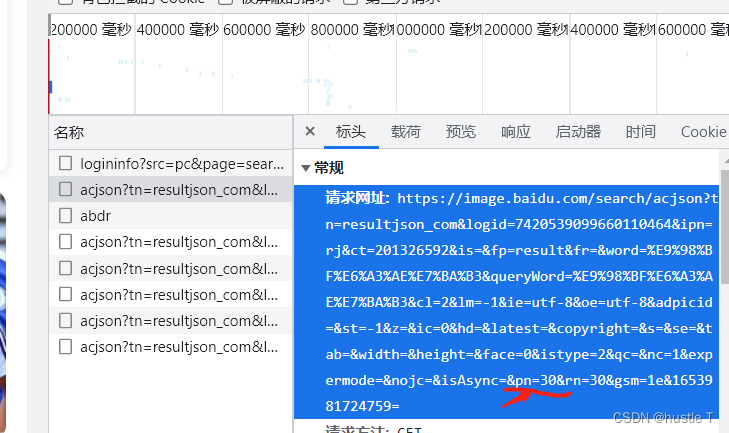
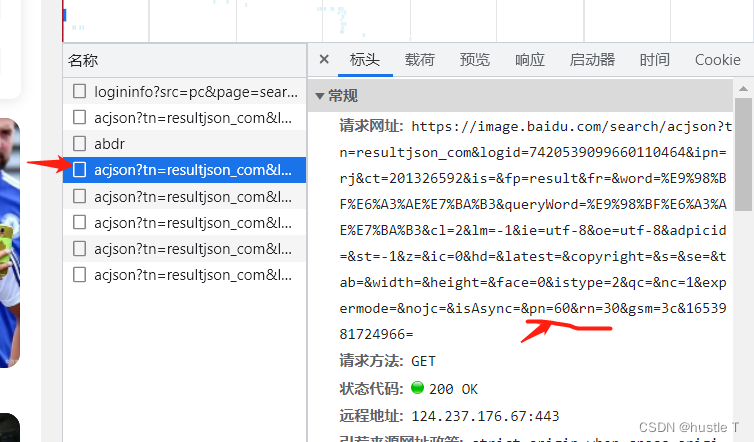
那么思路懂了,代码如下。还有一点是爬虫访问百度图片,很可能会遇到百度验证和被发现,弹出forbidden spider 。要去伪装自己是一个浏览器的样子。在你的请求标头中,下来浏览器的各种参数就行了!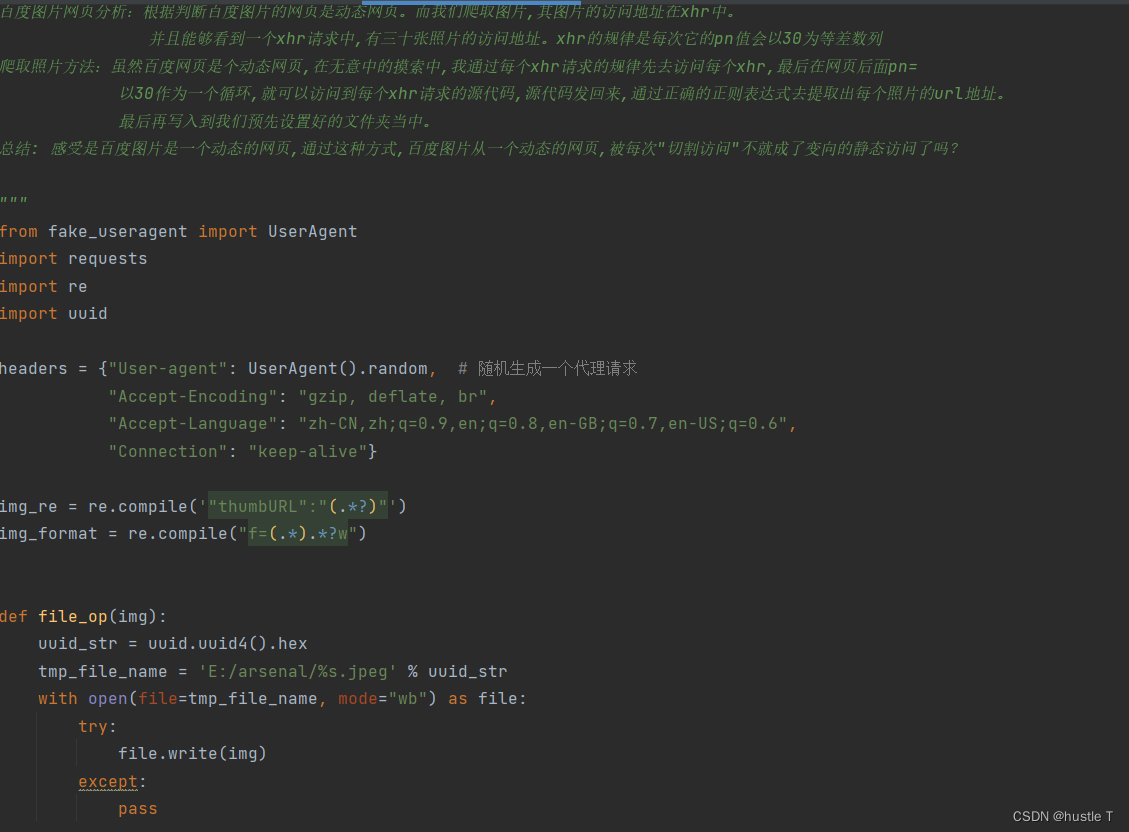
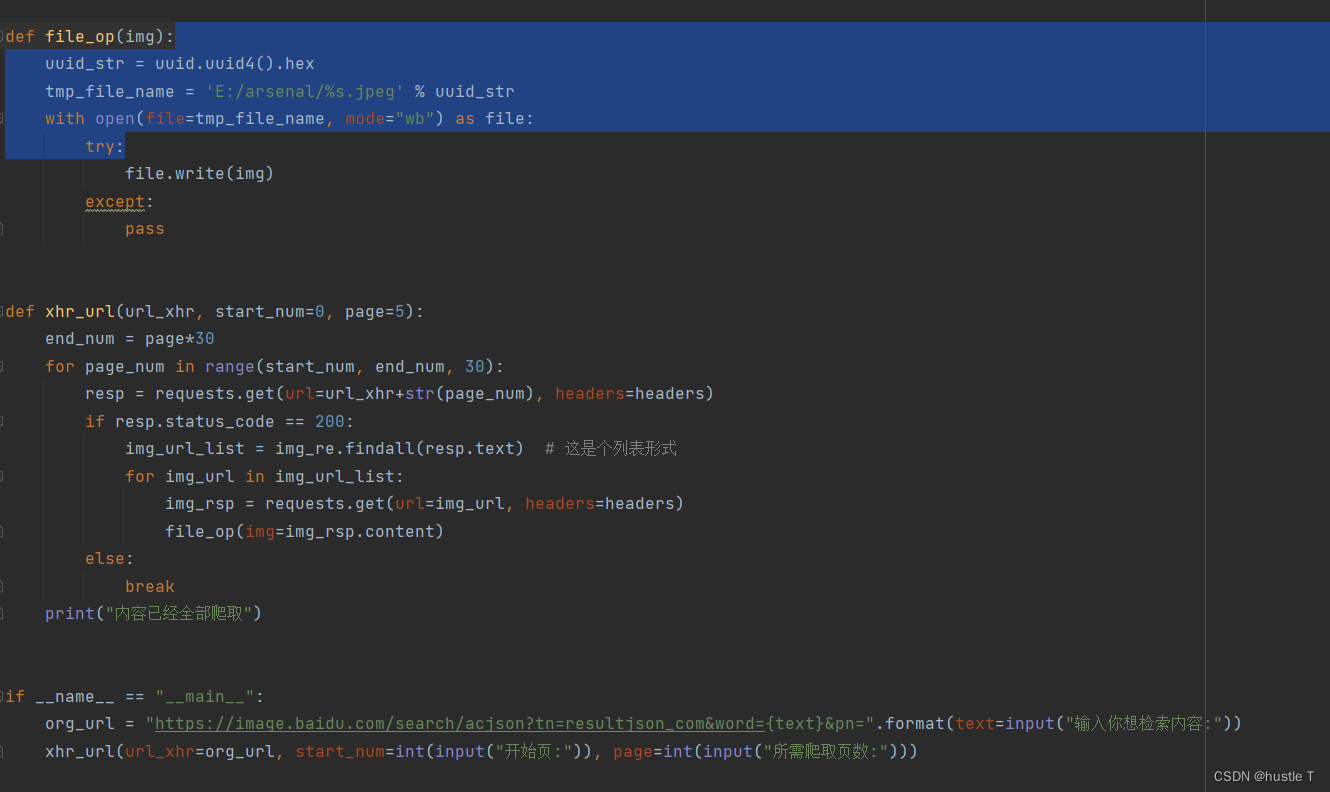
from fake_useragent import UserAgent
import requests
import re
import uuid
headers = {"User-agent": UserAgent().random, # 随机生成一个代理请求
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive"}
img_re = re.compile('"thumbURL":"(.*?)"')
img_format = re.compile("f=(.*).*?w")
def file_op(img):
uuid_str = uuid.uuid4().hex
tmp_file_name = 'E:/arsenal/%s.jpeg' % uuid_str
with open(file=tmp_file_name, mode="wb") as file:
try:
file.write(img)
except:
pass
def xhr_url(url_xhr, start_num=0, page=5):
end_num = page*30
for page_num in range(start_num, end_num, 30):
resp = requests.get(url=url_xhr+str(page_num), headers=headers)
if resp.status_code == 200:
img_url_list = img_re.findall(resp.text) # 这是个列表形式
for img_url in img_url_list:
img_rsp = requests.get(url=img_url, headers=headers)
file_op(img=img_rsp.content)
else:
break
print("内容已经全部爬取")
if __name__ == "__main__":
org_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&word={text}&pn=".format(text=input("输入你想检索内容:"))
xhr_url(url_xhr=org_url, start_num=int(input("开始页:")), page=int(input("所需爬取页数:")))
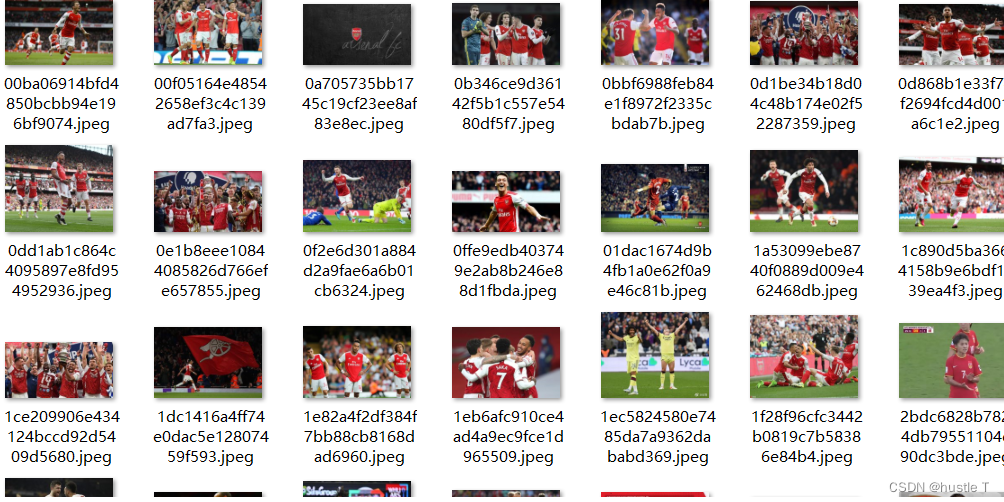
运行结果看一看吧
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.dbeile.cn/news/2267.html








最新文章
-

卖二手手机去哪里卖(卖二手手机在哪卖比较好)
2025-12-15 -
卫星地图下载手机版(卫星地图下载手机版官方)
2025-12-15 -
三千左右性价比高的手机(三千左右性价比高的手机排行榜)
2025-12-15 -

vivo手机配件(vivo手机配件真伪查询)
2025-12-15 -

手机客户端怎么登录(手机客户端怎么登录两个微信)
2025-12-15 -

oppo手机真伪(oppo手机真伪查询)
2025-12-15 -

iphone备份到新手机(iphone备份到新iphone)
2025-12-15 -

小米手机定位(小米手机定位华为手机位置怎么设置)
2025-12-15
热门文章
-

碰一碰收款码申请攻略(详细步骤和注意事项)
2024-12-26 -

33个适合新手投稿的公众号!
2024-12-12 -

2023年中国十大搜索引擎排名及分析
2024-12-08 -

微信碰一碰支付设置详解,如何轻松开启你的移动支付新体验_权限解释落实
2024-12-20 -
数字人民币真的来了!已进入微信,碰一碰就能付钱,教你怎么使用
2024-12-20 -

百度地图在哪看交易记录 百度地图看交易记录方法【教程】
2024-12-12 -

华为副总裁邓泰华一行到访智行者 推进双方深入合作
2024-12-08 -

400106(信威集团)的重组已经成功。信威集团在2024年完成了与天骄的重组,
2024-12-08