pytesseract 不能识别_你还在用腾讯,百度API来进行图片文字识别?out了

遥想当年,图片文字识别不是很牛的时代,小编都是边看图片,边码字,那个年代还有专门的人负责打字,堪称打字员。随着技术的不断进步,图片 文字识别的精度越来越高,很多课本都可以扫描,然后使用图片识别工具进行文字的提取工作。
当然你可以完全使用腾讯,或者百度的API 进行图片文字的识别,它们都有自己的接口。作为新型一代的科技人员的小编,怎么会直接使用API,自己动手搞起来

OCR 文字识别
OCR (Optical Character Recognition,光学字符识别)是指电子设备检查图片上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
OCR的原理:
图像输入、预处理:
二值化:对摄像头拍摄的图片,大多数是彩色图像,为了让计算机更快的,更好的识别文字,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
噪声去除:根据噪声的特征进行去噪,就叫做噪声去除
倾斜较正:拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
版面分析:将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
字符切割、字符识别、版面恢复、后处理、校对等等

文字识别Tesseract
说到文字识别,不得不提Tesseract,Tesseract现在已经升级到6.0以上,幸运的是,Tesseract提供了exe的可安装文件(私信小编:tesseract,获取文件,当然,你也可以直接在网站上下载,速度很慢,小编已经共享网盘)
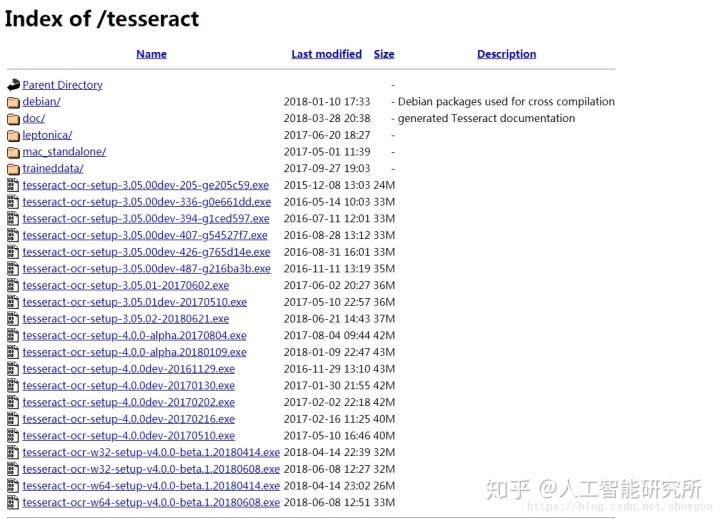
刚开始小编使用的是3.0.2版本,安装完成后,直接在CMD命令行中输入如下:
软件会自动在本文件夹下,生成一个stdout.txt的文件,识别效果还可以
pytesseract 是python下的的文字识别库,但是pytesseract的运行,需要tesseract的软件,所以仍然需要安装esseract。这里是小编踩到的第一个坑。想着直接安装pytesseract,就可以运行图片识别。
虽然小编安装了tesseract 但是版本太低,代码运行提示要高于3.0.5,怎奈小编刚开始安装的是3.0.2
卸载重新下载,本次小编直接安装 了5.0以上的版本,安装完成后,直接在cmd下输入
软件提示TESSDATA_PREFIX 的环境变量有问题,找不到可以使用的语言检测模型,这里是小编踩到的第二坑,直接新建一个环境变量
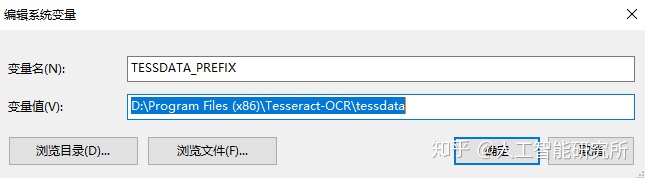
环境变量
环境变量配置完成后,再次输入
软件正常运行,但是无法提取结果,按照小编的理解,会在文件夹下有一个stdout的txt文件,这里是小编踩的第三个坑,4.0以上版本不在这里输入stdout ,而是随便一个文件名称,输入
便成功识别了文字,且识别效果比3.0版本要好

左 3.0 右5.0
ok ,当你安装好了tesseract,便可以进行图片文字的识别工作,但是这样的话,每张图片都敲一次命令,太费事,还好小编会python 啊,毕竟人生苦短吗
下期带你看如何使用python与tesseract, 我们不仅识别文字,还可以提取文字在图片的位置
头条号:人工智能研究所
微@信搜索:启示AI科技,
体验不一样的AI工具
微信搜索小程序:AI人工智能工具

本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.dbeile.cn/news/47.html







最新文章
-

卖二手手机去哪里卖(卖二手手机在哪卖比较好)
2025-12-15 -
卫星地图下载手机版(卫星地图下载手机版官方)
2025-12-15 -
三千左右性价比高的手机(三千左右性价比高的手机排行榜)
2025-12-15 -

vivo手机配件(vivo手机配件真伪查询)
2025-12-15 -

手机客户端怎么登录(手机客户端怎么登录两个微信)
2025-12-15 -

oppo手机真伪(oppo手机真伪查询)
2025-12-15 -

iphone备份到新手机(iphone备份到新iphone)
2025-12-15 -

小米手机定位(小米手机定位华为手机位置怎么设置)
2025-12-15
热门文章
-

碰一碰收款码申请攻略(详细步骤和注意事项)
2024-12-26 -

33个适合新手投稿的公众号!
2024-12-12 -

2023年中国十大搜索引擎排名及分析
2024-12-08 -

微信碰一碰支付设置详解,如何轻松开启你的移动支付新体验_权限解释落实
2024-12-20 -
数字人民币真的来了!已进入微信,碰一碰就能付钱,教你怎么使用
2024-12-20 -

百度地图在哪看交易记录 百度地图看交易记录方法【教程】
2024-12-12 -

华为副总裁邓泰华一行到访智行者 推进双方深入合作
2024-12-08 -

400106(信威集团)的重组已经成功。信威集团在2024年完成了与天骄的重组,
2024-12-08